About

Data Analytics Engineer & Data Science Enthusiast
Leveraging data-driven strategies to optimize business decisions and architect scalable, high-impact solutions.
- Email: raj.ar@northeastern.edu
- Phone:+91-9065704710
- City: Bengaluru, KA - India
- Roles: Senior Data Engineer, Data Engineer Researcher, Software Engineer - Data/Backend, Freelance Full Stack Data Engineer
- Companies: Abecedarian, IBM, Vittude, B2B Freelance Data Engineer
- Latest Degree: Masters of Science
- Alma Mater: Northeastern University (MS)
Iowa State University (BS)
- Specialization: Data Engineering & Analytics, Management Information Systems
- Interest: Big Data Pipeline Creation and Management, Data Analytics and Visualization, Database Management, Cloud Platforms
Every dataset tells a story—I make sure it's the right one. At the intersection of technology and analytics, I engineer scalable data pipelines, automate workflows, and extract meaningful insights. That’s my world. At the intersection of technology and analytics, I’ve worked with leading organizations like IBM, Vittude, and 7bi, building scalable data solutions that turn complexity into clarity.
My journey through Northeastern University and Iowa State University wasn’t just about degrees— it was a battleground for mastering data. From engineering robust pipelines to crafting compelling analytics, I’ve honed the skills that make data work for businesses, not the other way around.
Beyond the code and queries, big data is my playground, visualization is my canvas, and cloud solutions are my launchpad. Whether it's architecting real-time data pipelines or uncovering trends that drive decisions, I don’t just analyze data— I bring it to life. 🚀
Facts
Immersed in the vast expanse of the data universe, I've honed a unique expertise.
Through unwavering dedication to projects, client assistance, and ceaseless learning, I've achieved the following milestones:
ETL/ELT Tools Used
RDBMS and NoSQL Experienced
Cloud Platforms
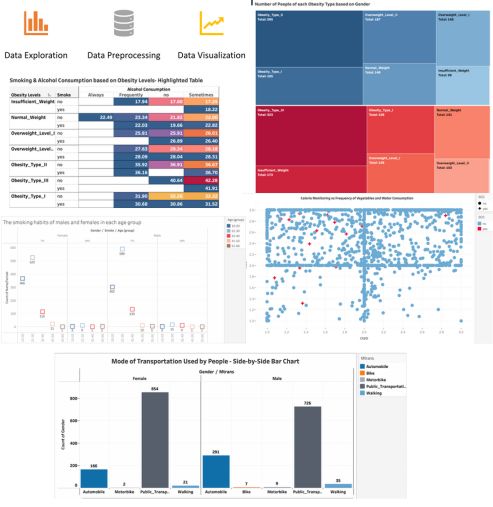
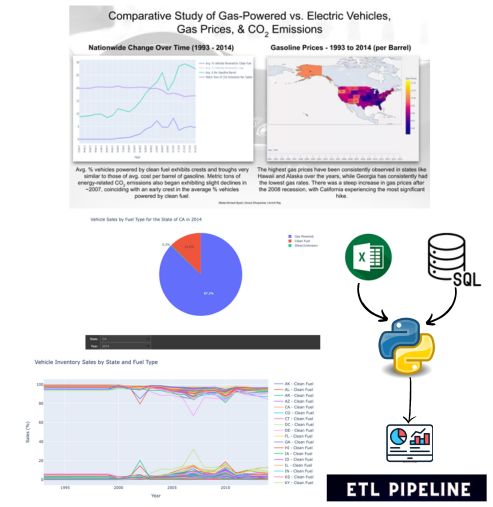
Projects
Skills
With a foundation in data engineering, I bring a blend of technical proficiency and analytical acumen to transform raw data into actionable insights.
Career Highlights
SUMMARY
Product-focused Data Engineer with 5 years architecting scalable real-time and batch data platforms using Python, SQL, PySpark, Kafka, dbt, Airflow, and Terraform across AWS and Databricks. Delivered outcomes across LLM-powered analytics and ML pipelines, including 40% latency reduction, 30% uptime improvement, and 15% Redshift cost savings. Build production-grade ETL and streaming systems that power product analytics, feature adoption, and executive decision-making across cross-functional engineering teams.
PROFESSIONAL EXPERIENCE
Senior Data Engineer
Abecedarian - Boston, MA - USA & Bengaluru, KA - India
Nov 2024 – Present
- Delivered a modular, end-to-end logistics analytics platform processing ~2M daily records across PostgreSQL, AWS, and Python, simulating enterprise-scale supply chain workloads.
- Designed and deployed reproducible onboarding and documentation workflows using Obsidian, DBeaver, Draw.io, and VS Code to reduce onboarding time by 40%.
- Built KPI-driven joins and ETL modeling strategy aligned with business use cases, enabling mock executive dashboards for internal planning scenarios.
- Packaged all deliverables as a full-stack case study for GitHub showcasing real-world architecture, tool integration, and analytics readiness.
- Tech Stack: PostgreSQL, Python, Pandas, AWS (S3, Lambda), Obsidian, DBeaver, Draw.io
Data Engineer
Abecedarian, Boston, MA - USA
Sep 2023 - Nov 2024
- Architected real-time customer engagement analytics pipelines in Databricks using PySpark, SQL, and dbt to reduce latency by 40% and boost AI-based feature engagement by 15%.
- Developed A/B testing and behavioral segmentation logic to surface product bottlenecks and inform experimentation loops.
- Built dbt model lineage with Airflow DAGs and CI workflows for seamless daily execution across S3 and Glue ingestion.
- Tech Stack: Databricks, PySpark, SQL, dbt, Airflow, AWS (S3, Glue, Lambda), Tableau
Senior Data Engineer Intern/Co-op - Data & AI
IBM, San Jose, CA
Jun 2022 - Dec 2022
- Led migration of IBM Db2 pipeline components from PL/SQL to REST API, improving processing efficiency by 30% and access latency by 50% across geospatial datasets.
- Tech Stack: IBM Db2, SQL, REST APIs, CI/CD, Geospatial Data, AWS (Redshift, Lambda), Power BI
Data Engineer
Vittude, Sao Paulo, Brazil
Jan 2020 - Aug 2021
- Engineered a real-time ingestion pipeline using Kafka (MSK), S3, and Lambda with 99.4% reliability and integrated KPI tracking dashboards using Redshift and Tableau.
- Tech Stack: PostgreSQL, Python (NumPy, Pandas, PySpark), Django, DBT, AWS (S3, Redshift, Lambda, MSK Kafka), Tableau
Data Engineer Intern
Vittude, Sao Paulo, Brazil
May 2018 - Jan 2019
- Automated ingestion and transformation pipelines via AWS Glue and Lambda, cutting weekly KPI reporting delays by 9 hours.
- Tech Stack: AWS (Glue, Glue Crawler, Lambda, Redshift, S3), Power BI
EDUCATION
Master of Science in Data Analytics Engineering
Northeastern University, Boston, MA, USA
Sept 2021 - Jul 2023
Focused on cloud-scale data engineering, machine learning, and pipeline design using PySpark, SQL, and AWS infrastructure.
Bachelor of Science in Management Information Systems
Iowa State University, Ames, IA, USA
Aug 2016 - May 2020
Specialized in database design, business systems analysis, and enterprise data workflows.
Portfolio Projects
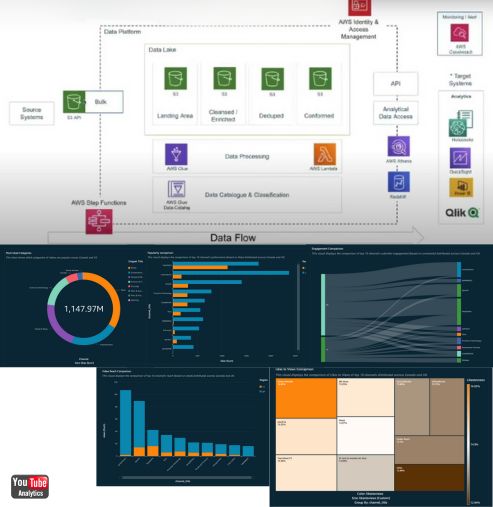
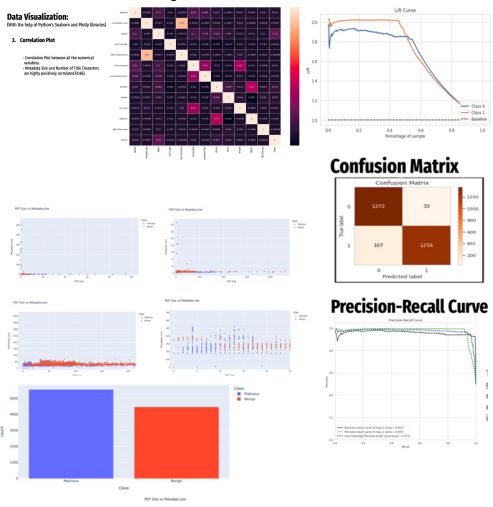
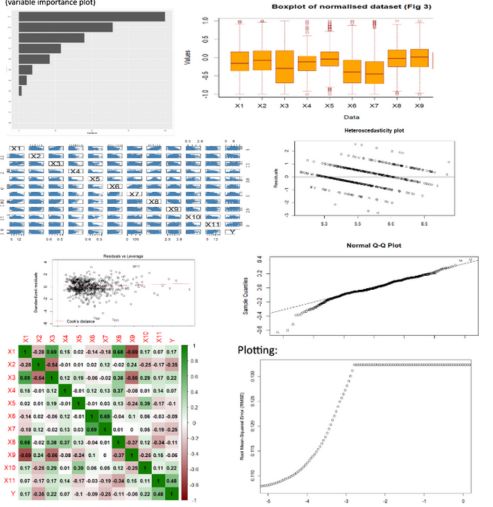
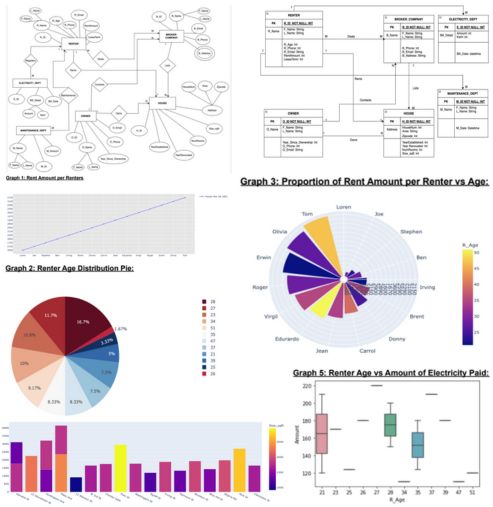
Contact
Location:
Bengaluru, KA - India - 560048
Email:
raj.ar@northeastern.edu
Call:
+91(90657)-04710